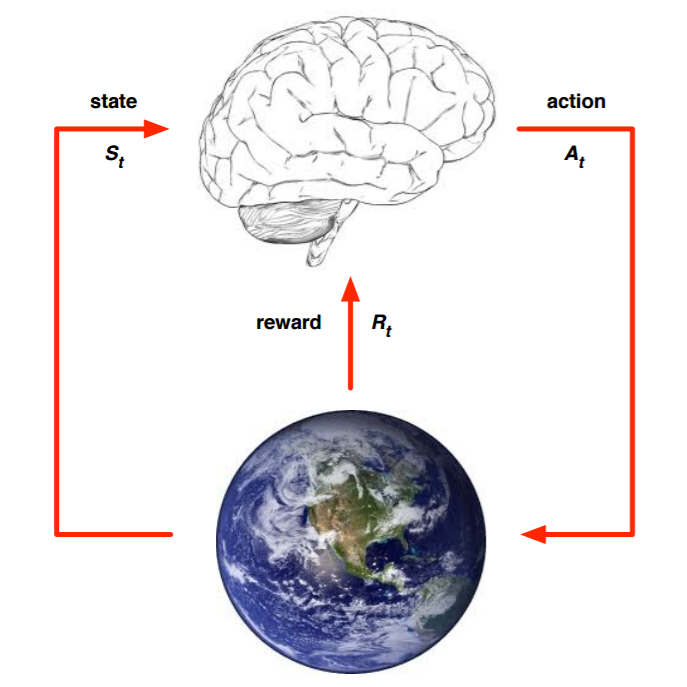
Reward is Enough
Desc: RL
Finished?: Yes
Tags: Paper
通用人工智能,是否能通过强化学习的奖励机制就实现
实现AGI,强化学习就够了?Sutton、Silver师徒联手:奖励机制足够实现各种目标
对reward构建AGI的可行性的分析和探讨
这篇文章实际上没有给出一个很好的方案通过reward来实现各种AGI的设计,但是给出了在每一种场景下的AGI的reward设计的设想把。和对用reward进行设计的可行性分析。
同时分析了:感知、社交、语言、泛化、模仿,这几个方面
类似地,如果人工智能体的经验流足够丰富,那么单一目标(例如电池寿命或生存)可能隐含地需要实现同样广泛的子目标的能力,因此奖励最大化应该足以产生一种通用人工智能。
这不久回到了最基础的问题,没有这种长线以及大量数据交互以及全面场景的经验流,来支撑这样一个AGI的学习,所以这不也是在现阶段上纸上谈兵嘛?
对这篇论文我的总结是,我不推荐详细阅读,我觉得收益有限,太理想化,其实和强化学习本身的假设也没有太多新东西,我们可以假设强化学习能带来一个AGI,但是对应的约束和限制确实是有点多了。